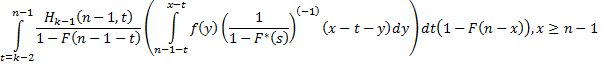|
Программные системы и вычислительные методы
Правильная ссылка на статью:
Труб И.И.
О распределении количества bitmap-индексов для произвольного потока занесения записей в базу данных
// Программные системы и вычислительные методы.
2017. № 1.
С. 11-21.
DOI: 10.7256/2454-0714.2017.1.21790 URL: https://nbpublish.com/library_read_article.php?id=21790
О распределении количества bitmap-индексов для произвольного потока занесения записей в базу данных
Труб Илья Иосифович
кандидат технических наук
ведущий инженер-программист, ООО "Исследовательский центр Samsung"
127018, Россия, г. Москва, ул. Двинцев, 12, оф. C
Trub Ilya
PhD in Technical Science
Senior Software Engineer, Samsung Research Center Ltd.
127018, Russia, Moscow, ul. Dvintsev, 12, of. C

|
itrub@yandex.ru
|
|
 |
Другие публикации этого автора
|
|
|
DOI: 10.7256/2454-0714.2017.1.21790
Дата направления статьи в редакцию:
24-01-2017
Дата публикации:
31-03-2017
Аннотация:
Предметом исследования является задача вычисления для интервала времени заданной длины распределения вероятностей количества единичных интервалов, на которых происходит по крайней мере одно событие некоторого случайного потока, заданного произвольным распределением вероятностей. Прикладное значение данной задачи заключается в том, что ее решение дает оценку количества bitmap-индексов, попадающих в результат запроса к базе данных, отфильтрованного по диапазону времени. Объектом исследования является математическая модель задачи, построенная средствами теории вероятностей, и методы получения с ее помощью численных результатов. Методологией исследования является детальная декомпозиция случайного потока событий с учетом прикладной логики решаемой задачи и вывод на основе методов теории вероятностей уравнений, которым удовлетворяет искомая функция распределения. Важным элементом методологии является использование аппарата преобразований Лапласа и применение теоремы о свертке. Основным результатом работы является постановка оригинальной задачи теории массового обслуживания и получение ее решения в виде системы интегральных рекуррентных уравнений для набора вспомогательных кусочно-непрерывных функций, совокупность которых позволяет получить итоговую функцию. Сформулирован вычислительный алгоритм решения полученной системы. Показано, что для случая экспоненциального распределения непосредственно получаемое ввиду его простоты решение удовлетворяет системе интегральных уравнений.
Ключевые слова:
теория массового обслуживания, случайный поток событий, плотность распределения вероятностей, двоичный индекс, экспоненциальное распределение, условная вероятность, интегральное уравнение, преобразование Лапласа, свёртка, граничные условия
Abstract: The subject of the study is the problem of calculating distribution of probabilities of the number of unit intervals for a time interval of a given length, on which at least one event of some random flow predetermined by arbitrary probability distribution occurs. The applied value of this task is that its solution gives an estimate of the number of bitmap-indexes falling into the result of a query to a database filtered by a time range. The object of the study is the mathematical model of the problem constructed by means of the theory of probability, and the methods of obtaining numerical results with its usage. The methodology of the research is a detailed decomposition of the random flow of events, taking into account the applied logic of the problem being solved and the derivation on the basis of methods of probability theory of equations satisfied by the desired distribution function. An important part of the methodology is the use of the Laplace transform apparatus and the application of the convolution theorem. The main result of the study is the formulation of the original problem of queuing theory and the derivation of its solution in the form of a system of integral recurrence equations for a set of auxiliary piecewise continuous functions whose totality allows to obtain the final function. The author formulates a computational algorithm for solving the resulting system. The article shows that, for the case of an exponential distribution, the solution immediately obtained, because of its simplicity, satisfies the system of integral equations.
Keywords: queueing theory, random flow of events, probability density function, bitmap index, exponential distribution, conditional probability, integral equation, Laplace transformation, convolution, boundary conditions
Введение
Рассмотрим поток событий в непрерывном времени, описываемый стационарным случайным процессом с функцией распределения интервала между двумя последовательными событиями F(t). Шкала времени разбита на равные интервалы единичной длины. Назовем полуоткрытый единичный интервал [j;j+1) (j – целое число) помеченным, если он содержит хотя бы одно событие из потока. Интерес для нас представляет дискретная случайная величина, которую определим как количество помеченных интервалов на полуоткрытом интервале длины n временнОй шкалы. Так как поток событий предполагается стационарным, без ограничения общно(t)сти примем для упрощения дальнейших выкладок левую границу интервала за начало отсчета времени, т.е. интервал имеет вид [0;n). Целью является нахождение функции 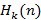 – вероятности того, что на интервале [0;n) ровно k единичных интервалов окажутся помеченными. – вероятности того, что на интервале [0;n) ровно k единичных интервалов окажутся помеченными.
Решение сформулированной задачи позволяет решить задачу о вычислении распределения для количества помеченных интервалов, накрываемых некоторым случайным отрезком, заданным своей функцией распределения. Прикладное значение данной задачи было подробно описано в [6]. Данная работа носит более математический, чем прикладной характер, но без нее не обойтись в поставленных в [6] прикладных задач. Там же эта задача сравнительно несложно была решена для случая 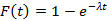 , т.е. для случая, когда входной поток является пуассоновским. Сделать это удалось благодаря тому, что в силу отсутствия последействия для экспоненциального распределения решение поставленной выше задачи записывается сразу в виде , т.е. для случая, когда входной поток является пуассоновским. Сделать это удалось благодаря тому, что в силу отсутствия последействия для экспоненциального распределения решение поставленной выше задачи записывается сразу в виде
|
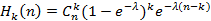
|
(1)
|
Разумеется, наличие решения только для одного – простейшего – распределения нельзя считать удовлетворительным результатом, т.к. в настоящее время хорошо известно, что потоки в информационных сетях и в глобальной сети Internet в целом не являются пуассоновскими, а наиболее близко к реальности моделируются другими распределениями, в частности, распределениями с тяжелым хвостом (heavy-tailed). Основополагающей в этом отношении явилась в свое время работа [9], задачи моделирования систем с такими потоками и подробная литература вопроса рассмотрены в [8]. С другой стороны, хорошо известно и то, что задачи теории массового обслуживания достаточно тяжело решаются для распределений произвольного вида. Решение, как правило, удается получить только в преобразованиях, а для доведения их до числа использовать методы вычислительной математики [3] – этот замечательный источник автор по-прежнему рекомендует заинтересованному читателю, желающему освоить теорию очередей и научиться применять ее методы на практике. Как справедливо отмечает в нем Л.Клейнрок, «иногда нас приводят в восторг красота и общность результатов, но чаще расстраивает отсутствие реального прогресса в теории. Нет, мы никогда не обещали Вам цветущего сада! Однако, мы не теряем веру в том, что изучение сможет вооружить нас ценными методами для практического решения многих неотложных на сегодняшний день задач». Сказанные более сорока лет назад, эти слова актуальны и по сей день.
Работа построена следующим образом. Общее решение поставленной задачи получено в виде системы рекуррентных интегральных соотношений (РИС) с обращением преобразований Лапласа в подынтегральной функции. Непосредственной подстановкой доказана справедливость РИС для экспоненциального распределения. Сформулирован алгоритм последовательного решения РИС, который опять-таки апробирован на функции экспоненциального распределения, т.к. для этого распределения решение получается непосредственно по определению и известно заранее. В заключении дана оценка полученных результатов и поставлены задачи для дальнейших исследований.
Вывод основных соотношений
Как уже было отмечено, для произвольного распределения F(t) формула (1) неприменима, т.к. вероятности наступления/ненаступления события на двух произвольных непересекающихся интервалах времени не являются независимыми и поэтому не подчиняются правилу умножения вероятностей, а, значит, и биномиальному распределению. Чтобы вычислить вероятность наступления события на заданном интервале, необходимо знать, в какой момент времени наступило последнее событие, не попавшее в этот интервал. Так и сделаем. Введем в рассмотрение новую двумерную дискретно-непрерывную случайную величину, которую определим как момент наступления последнего события на интервале (0;n), при условии, что события происходили ровно на k единичных подинтервалах и не происходили на n-k из них, и соответственно функцию плотности ее распределения, которую обозначим 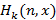 . Если эта функция известна, то решение исходной задачи немедленно вычисляется ее интегрированием от 0 до n по x. Выпишем следующие из определения свойства функции: . Если эта функция известна, то решение исходной задачи немедленно вычисляется ее интегрированием от 0 до n по x. Выпишем следующие из определения свойства функции:
1) 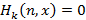 при k>n; при k>n;
2) при x≥n;
3) при x<k-1.
Далее построим вероятностную модель, связывающую изменения значения этой функции в зависимости от изменения ее параметров. Эта модель играет ключевую роль в решении. Рассмотрим два случая:
1) x<n-1;
2) n-1≤x<n
и для каждого из них выпишем соотношение для 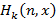 отдельно. Первый случай прост (рис 1). отдельно. Первый случай прост (рис 1).
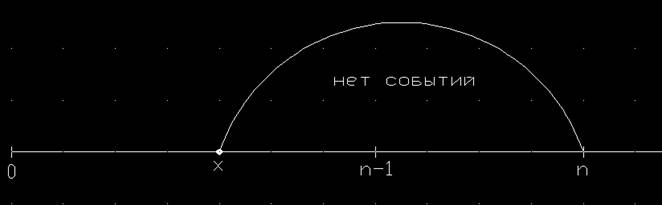
Рис. 1. Последнее событие произошло левее точки n-1.
Он означает, что все k помеченных подинтервалов должны оказаться внутри интервала (0;n-1), а на интервале (x;n) ни одного события не наступит. Имеем
|
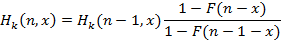
|
(2)
|
Знаменатель в правой части весьма важен – он учитывает наличие условной вероятности, т.к. первый сомножитель означает, что уже на интервале (x;n-1) событий нет. Таким образом, логическое прочтение дроби таково: «вероятность того, что интервал между событиями превышает n-x при условии, что он превышает n-1-x”.
Второй случай значительно сложнее и требует более тонких рассуждений (рис. 2). Здесь не обойтись без дальнейшей ретроспективы и учета момента наступления события, которое явилось последним на интервале (0;n-1) . Пусть оно произошло в момент t. Далее, на интервале (t;n-1) событий не должно было быть (событие t на интервале до n-1 – последнее!), после чего на интервале (n-1;x) могло произойти любое
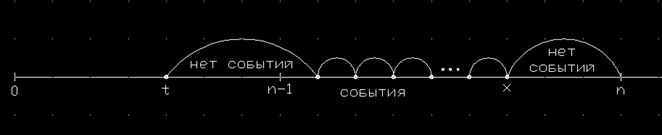
Рис.2. Последнее событие произошло правее точки n-1.
количество событий, последнее из них произошло в момент x и далее на интервале (x;n) опять событий не было. Математически рассуждение про любое количество событий интерпретируется следующим образом: сумма некоторого произвольного количества случайных величин, описываемых функцией распределения F, принимает значение x-t при условии, что первая случайная величина ограничена снизу значением n-1-t, все же остальные ограничены снизу нулем. Как известно, плотность распределения суммы случайных величин вычисляется как свертка функций плотности распределения величин-слагаемых. Заметим также, что нижней границей для t является значение k-2, т.к. в противном случае на интервале (0;n-1) не сможет оказаться k-1 помеченный интервал, а значит на (0;n) их не окажется n. Теперь для второго случая можно записать соотношение
|
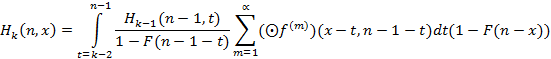
|
(3)
|
где функция f(x) есть плотность распределения для исходного потока событий, т.е. f(x)=F’(x). Выражение под знаком суммы обозначает m-кратную свертку функции f(x), вычисленную в точке x-t, причем нижний предел в первом интеграле этой свертки равен n-1-t. Для m=1 оно равно f(x-t), для m=3:
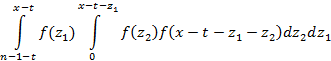
Сходимость ряда немедленно следует из того факта, что его n-ый член ограничен сверху значением 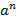 , где значение a равно , где значение a равно 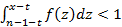 . .
Практическое значение (3) пока остается весьма невелико, т.к. мало понятно, что непосредственно делать с бесконечной суммой сверток. Для упрощения (3) воспользуемся стандартной для подобной ситуации техникой преобразования Лапласа, в частности, теоремой о свертке. Теория вопроса изложена в большом количестве учебной литературы, например, в [2]. Стандартным этот прием в теории очередей является по той причине, что практически во всех ее задачах приходится рассматривать суммы случайных величин, а значит, применять свертку. Применение же преобразования Лапласа позволяет перейти от «неудобной» свертки функций-оригиналов к «удобному» произведению функций-изображений. Введем обозначения:
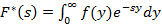 – преобразование Лапласа от плотности распределения f(y); – преобразование Лапласа от плотности распределения f(y);
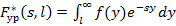 – «урезанное» преобразование Лапласа от плотности распределения f(y). Тогда, применив формулу для суммирования геометрической прогрессии, выражение (3) можно переписать в следующем виде: – «урезанное» преобразование Лапласа от плотности распределения f(y). Тогда, применив формулу для суммирования геометрической прогрессии, выражение (3) можно переписать в следующем виде:
|
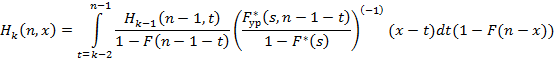
|
(4)
|
где (-1) обозначает обращение преобразования Лапласа, а (x-t) – не множитель, а значение, в котором это обращение вычисляется.
Таким образом, для функции Hk(n,x) мы получили рекуррентное соотношение, состоящее из выражений (2) и (4). Осталось выписать начальные условия, для того чтобы рекуррентные вычисления можно было инициализировать. Для этого предварительно напомним хорошо известную в теории восстановления [4] формулу для плотности распределения остаточной длительности случайной величины, что в теории очередей [3] интерпретируется как остаточное время ожидания события, когда наблюдение начинается в случайный момент времени:
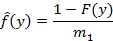
где F(y) – функция распределения исходной случайной величины, 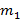 – ее математическое ожидание (или, по-другому, первый момент). Именно таковой и является случайная величина, описывающая момент времени наступления самого первого события (считая от начала наблюдения – точки 0). С другой стороны, – ее математическое ожидание (или, по-другому, первый момент). Именно таковой и является случайная величина, описывающая момент времени наступления самого первого события (считая от начала наблюдения – точки 0). С другой стороны, 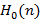 есть вероятность того, что остаточная длительность превысит n. Поэтому есть вероятность того, что остаточная длительность превысит n. Поэтому
|
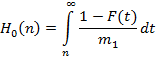
|
(5)
|
Выведем теперь формулу для 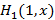 , т.к. эта функция также не попадает под общий случай. Событие, плотность распределения вероятностей которого описывает эта функция, заключается в следующем: x является суммой произвольного количества случайных величин, первая из которых описывается функцией , т.к. эта функция также не попадает под общий случай. Событие, плотность распределения вероятностей которого описывает эта функция, заключается в следующем: x является суммой произвольного количества случайных величин, первая из которых описывается функцией 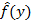 , а все остальные – функцией f(y), и на интервале (x,1) событий нет. Применяя ту же технику, что и при выводе (4), получаем , а все остальные – функцией f(y), и на интервале (x,1) событий нет. Применяя ту же технику, что и при выводе (4), получаем
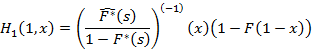
Упростим выражение, стоящее под знаком обращения преобразования Лапласа. Воспользовавшись формулой для остаточной длительности и «интегральным» свойством преобразования Лапласа (ибо F(t) есть интеграл от плотности распределения от 0 до t), получим
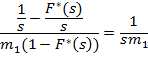
Обращение получившейся функции равно 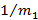 . Таким образом, получаем . Таким образом, получаем
|
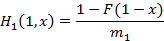
|
(6)
|
Подтвердим (6) простым логическим рассуждением. Нетрудно видеть, что 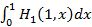 интерпретируется как вероятность того, что на интервале (0;1) наступит хотя бы одно событие, т.к. в этом случае какое-то событие обязательно окажется последним, а мы интегрируем по всем возможным моментам его наступления. А это есть вероятность того, что остаточная длительность случайной величины окажется меньше 1. Проинтегрировав теперь правую часть (6) от 0 до 1 с заменой переменной y=1-x как раз и получим интерпретируется как вероятность того, что на интервале (0;1) наступит хотя бы одно событие, т.к. в этом случае какое-то событие обязательно окажется последним, а мы интегрируем по всем возможным моментам его наступления. А это есть вероятность того, что остаточная длительность случайной величины окажется меньше 1. Проинтегрировав теперь правую часть (6) от 0 до 1 с заменой переменной y=1-x как раз и получим 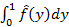 , т.е. именно эту вероятность. , т.е. именно эту вероятность.
Таким образом, нами построена совокупность рекуррентных интегральных соотношений (2), (4), (5), (6), полностью определяющая множество функций , которую, напомним, во введении мы сокращенно назвали РИС. В оставшейся части работы РИС будет исследована на достоверность и наличие алгоритма решения в общем случае.
Случай экспоненциального распределения
Можно ли с уверенностью говорить о том, что полученная РИС верна? Не была ли допущена какая-либо неточность в вероятностной логике, полностью искажающая итоговое решение? Хорошей проверкой в такой ситуации было бы получить для какого-либо распределения F(y) набор функций «в лоб», т.е. исходя исключительно из каких-то особых свойств F(y), а затем, подставив полученное решение в РИС, проверить, выполняются ли они. Положительный результат такой проверки подтвердил бы достоверность РИС, т.к. при ее выводе мы в своих рассуждениях не делали никаких предположений об F(y), предполагая распределение вероятностей абсолютно произвольным. Разумеется, для проверки наиболее подходит экспоненциальное распределение (и, пожалуй, только оно, т.к. никакое другое не обладает свойством отсутствия последействия), его и используем. Приступим к первому этапу проверки, а именно – непосредственному получению .
Исходя из элементарной вероятностной логики и свойств экспоненциального распределения, оно записывается сразу:
|
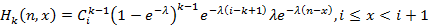
|
(7)
|
где k-1≤i≤n-1. Чтобы убедиться, что это действительно так, вспомним [6], что для экспоненциального распределения
|
|
(8)
|
Следовательно, необходимо убедиться в справедливости равенства
|
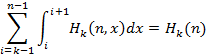
|
(9)
|
где в левую часть подставляется (7), а в правую – (8). Взяв в левой части (9) определенный интеграл, получим
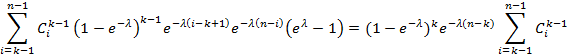
То, что последняя сумма равна 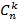 , легко доказывается индукцией по n и применением непосредственно проверяемого тождества , легко доказывается индукцией по n и применением непосредственно проверяемого тождества 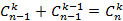 . Таким образом, справедливость (7) для экспоненциального распределения доказана. Теперь нужно доказать, что (7) удовлетворяет общему решению (2), (4), (5), (6). . Таким образом, справедливость (7) для экспоненциального распределения доказана. Теперь нужно доказать, что (7) удовлетворяет общему решению (2), (4), (5), (6).
Сначала проверим (2). Вычислив с помощью (7) и 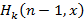 для любого i, i≤x<i+1, получим для любого i, i≤x<i+1, получим 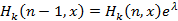 . Тогда, чтобы доказать справедливость (2), нужно показать, что для экспоненциального распределения выполняется тождество . Тогда, чтобы доказать справедливость (2), нужно показать, что для экспоненциального распределения выполняется тождество
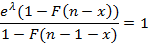
в чем легко убедиться непосредственной подстановкой.
Займемся теперь проверкой (4), т.е. случаем n-1<x≤n. Он соответствует значению i=n-1. Левая часть уравнения принимает вид
|
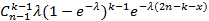
|
(10)
|
Сформируем правую часть. На каждом участке i≤t<i+1, i=(k-2)…(n-2) с помощью элементарных выкладок (проверка предоставляется читателю) имеем
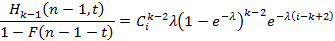
Теперь нужно найти обратное преобразование Лапласа для соответствующей части уравнения (4) , проинтегрировать на каждом единичном отрезке по t, просуммировать по i, умножить на 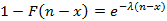 и полученный результат сравнить с (10). Выполняем этот план. и полученный результат сравнить с (10). Выполняем этот план.
Сделав необходимые выкладки, получим, что обратному преобразованию подлежит следующая функция
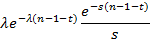
Нас интересует значение обращенной функции в точке x-t. Т.к. x≥n-1, то x-t≥n-1-t, и обратное преобразование от дроби (зависящей от s) равно 1 (проверяется по любому источнику, содержащему таблицы преобразований Лапласа, например, [2]), а полностью обращенное выражение равно 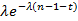 . Интегрирование по t в пределах от i до i+1 дает . Интегрирование по t в пределах от i до i+1 дает
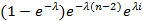 . Собрав теперь воедино всё полученное содержимое правой части (4) и просуммировав по i, получим . Собрав теперь воедино всё полученное содержимое правой части (4) и просуммировав по i, получим
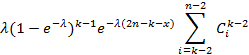
Сравнив это с (10), делаем вывод, что для завершения доказательства справедливости РИС для экспоненциального распределения осталось доказать тождество
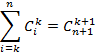
что легко сделать методом математической индукции по n. Итак, мы полностью убедились в достоверности построенного общего решения.
Получение решения с помощью РИС
Итак, можно сделать заключение, что РИС верны. Осталось рассмотреть вопрос, каким образом их использовать на практике для фактического получения решения и какие проблемы при этом могут возникнуть. Исходя из вида РИС, алгоритм такого использования нетрудно сформулировать.
1) Из (6) непосредственно получаем 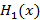 , из (5) получаем . , из (5) получаем .
2) Из (2), зная , получаем 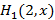 для 0≤x<1. для 0≤x<1.
3) Из (4), зная 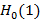 , получаем для 1≤x<2. , получаем для 1≤x<2.
4) Из (2), зная , получаем 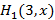 . При этом важно отметить, что так как описывается разными функциями на отрезках (0;1) и (1;2), на этих отрезках тоже будет разной. Обобщение этого обстоятельства на весь алгоритм позволяет понять, почему не только для экспоненциального распределения, но и в общем случае функция будет менять свое аналитическое представление на каждом единичном интервале. . При этом важно отметить, что так как описывается разными функциями на отрезках (0;1) и (1;2), на этих отрезках тоже будет разной. Обобщение этого обстоятельства на весь алгоритм позволяет понять, почему не только для экспоненциального распределения, но и в общем случае функция будет менять свое аналитическое представление на каждом единичном интервале.
5) Из (2), зная 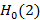 , получаем для 2≤x<3. , получаем для 2≤x<3.
6) Последовательно находим 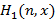 для любого n. для любого n.
7) Зная , находим 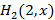 из (4). из (4).
8) Зная и , находим 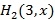 . .
Дальнейшая схема последовательных вычислений понятна. Сделаем в связи с описанным алгоритмом важное замечание. В тех его пунктах, где предполагается применить уравнение (4), сделать это на самом деле не так-то просто из-за необходимости обращения преобразования Лапласа. С легкостью оно вычисляется только для экспоненциального распределения, а для любого другого наличие «урезанного» множителя значительно осложняет вычисления и ухудшает понимание формулы. В самом деле, уже получение «урезанного» преобразования Лапласа с ненулевым нижним пределом интегрирования может дать весьма громоздкий результат, а наличие его в обращаемой функции уже и вовсе делает задачу обращения в общем случае практически неразрешимой. Поэтому представляется разумным переписать (4), вынеся «урезанную» плотность распределения из-под операции свертки. Это добавит в формулу лишнюю операцию интегрирования, но зато сделает ее более понятной, а обращаемую функцию более наглядной. Сделаем это. (4) приобретает следующий вид:
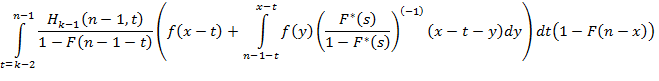
Обращаемая функция несколько упростилась, что позволит нам теперь упростить и всю формулу. Обращаемая функция раскладывается на слагаемые
`1/(1-F^(*)(s))-1`. Обратив каждое, получим
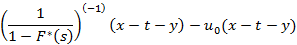
где 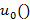 – дельта-функция Дирака (единичный импульс). Математикам хорошо известно, что эта функция никогда не возникает в конечном результате сама по себе, ее появление обязательно происходит в качестве части некоей подынтегральной функции, а интеграл подвергается дальнейшим преобразованиям и заменам. Так получилось и в нашем случае. Вот этот интеграл: – дельта-функция Дирака (единичный импульс). Математикам хорошо известно, что эта функция никогда не возникает в конечном результате сама по себе, ее появление обязательно происходит в качестве части некоей подынтегральной функции, а интеграл подвергается дальнейшим преобразованиям и заменам. Так получилось и в нашем случае. Вот этот интеграл:
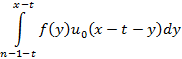
Т.к. ноль дельта-функции совпадает с одним из пределов интегрирования, то согласно «просеивающему» свойство дельта-функции [3] этот интеграл равен f(x-t), что позволяет существенно упростить выражение, стоящее в скобках в (4), записав его в виде
|
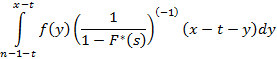
|
(11)
|
Убедимся, что это действительно так опять-таки на примере экспоненциального распределения. В предыдущем разделе мы показали, что выражение, стоящее в скобках, преобразуется для этого распределения к виду . Покажем, что к этому же виду можно привести и (11). Обращаемая функция принимает вид λ/s +1, что после обращения дает 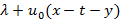 , и (11) раскладывается на сумму двух интегралов. Первый интеграл равен , и (11) раскладывается на сумму двух интегралов. Первый интеграл равен 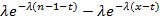 , второй в силу уже применявшегося нами просеивающего свойства дельта-функции равен , второй в силу уже применявшегося нами просеивающего свойства дельта-функции равен 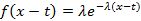 , что успешно завершает проверку. , что успешно завершает проверку.
Итак, окончательно сведем воедино все уравнения:
Заключение
Система уравнений (12) дает общее решение поставленной задачи. Теперь наибольший интерес представляет доведение этого решения до числа, причем для распределений, не являющихся экспоненциальным, а также последующее изучение особенностей полученных функций. На этом этапе применяемый математический аппарат сместится из теории вероятностей и математического анализа в область численных методов – численного интегрирования, вычисления специальных функций и обращения преобразований Лапласа. Понятно, что удобство реализации РИС во многом зависит от того, какой является функция 1/(1-F*(s)). Возможно, что для каких-то распределений ее можно обратить, пусть даже результат будет выражен через специальные функции – здесь огромную помощь может оказать фундаментальный труд [1]. Если же требуемая функция будет отсутствовать даже там, придется применить методы численного обращения [5]. Особенности расчетов по формулам (12) численными методами для различных функций распределения, включая выбор конкретного метода, управление точностью вычислений, а также программную реализацию автор рассчитывает рассмотреть в следующей работе.
` `
Библиография
1. Бейтмен Д., Эрдейи А. Таблицы интегральных преобразований. Том 1: Преобразования Фурье, Лапласа, Меллина.-М.: Наука, 1969. 344 с.
2. Диткин В.А., Прудников А.П. Интегральные преобразования и операционное исчисление. М.: ГИФМЛ, 1961. 524 с.
3. Клейнрок Л. Теория массового обслуживания.-М.: Машиностроение, 1979. 432 с.
4. Кокс Д.Р., Смит В.Л. Теория восстановления.-М.: Советское радио, 1967. 300 с.
5. Крылов В.И., Скобля Н.С. Методы приближенного преобразования Фурье и обращения преобразования Лапласа. - М. Наука, 1974. 312 с.
6. Труб И.И. Аналитическое вероятностное моделирование bitmap-индексов // Программные системы и вычислительные методы. – 2016. – № 4. – С. 315-323. DOI: 10.7256/2305-6061.2016.4.2109
7. Труб И.И. Объектно-ориентированное моделирование на С++.-СПб, Питер, 2006. 416 с.
8. Discrete-Event Simulation. 3rd ed. / J. Banks, J. S. Carson, B. L. Nelson, D. M. Nicol. — Prentice Hall: Englewood Cliffs, NS, 2000. - 594 p.
9. Paxson V., Floyd S. Wide-area traffic: the failure of Poisson modeling. // IEEE/ACM Transactions on Networking.-1995.-June.-P.226-244.
References
1. Beitmen D., Erdeii A. Tablitsy integral'nykh preobrazovanii. Tom 1: Preobrazovaniya Fur'e, Laplasa, Mellina.-M.: Nauka, 1969. 344 s.
2. Ditkin V.A., Prudnikov A.P. Integral'nye preobrazovaniya i operatsionnoe ischislenie. M.: GIFML, 1961. 524 s.
3. Kleinrok L. Teoriya massovogo obsluzhivaniya.-M.: Mashinostroenie, 1979. 432 s.
4. Koks D.R., Smit V.L. Teoriya vosstanovleniya.-M.: Sovetskoe radio, 1967. 300 s.
5. Krylov V.I., Skoblya N.S. Metody priblizhennogo preobrazovaniya Fur'e i obrashcheniya preobrazovaniya Laplasa. - M. Nauka, 1974. 312 s.
6. Trub I.I. Analiticheskoe veroyatnostnoe modelirovanie bitmap-indeksov // Programmnye sistemy i vychislitel'nye metody. – 2016. – № 4. – S. 315-323. DOI: 10.7256/2305-6061.2016.4.2109
7. Trub I.I. Ob''ektno-orientirovannoe modelirovanie na S++.-SPb, Piter, 2006. 416 s.
8. Discrete-Event Simulation. 3rd ed. / J. Banks, J. S. Carson, B. L. Nelson, D. M. Nicol. — Prentice Hall: Englewood Cliffs, NS, 2000. - 594 p.
9. Paxson V., Floyd S. Wide-area traffic: the failure of Poisson modeling. // IEEE/ACM Transactions on Networking.-1995.-June.-P.226-244.
|
 Рус
Рус